
In this post, we’ll explore some technical aspects of constructing a lightweight Python-based CDC system. However, the core focus here is on the techniques that unlock rapid iteration and efficiency, particularly when navigating significant uncertainty.
Change data capture (CDC) refers to the process of capturing changes made to data in a database and then delivering those changes in real-time to a downstream system. We’ll use PostgreSql and Kafka.
PoC: main module at GitLab and GitHub mirror
Latest version: GitLab and GitHub mirror

Power Up Your Agile: Problem Decomposition#
While many patterns and techniques contribute to agile development, I find problem decomposition to be particularly effective.
Problem decomposition is the process of breaking down a complex problem into smaller, more manageable, and easier-to-solve subproblems.
The idea is to use an agile approach and problem decomposition, a clear goal, start working, and iteratively identify the problems and solve them, one at a time.
At the beginning of the journey, we only know our goal:
To be efficient we need to embrace uncertainty and have a clear goal.
Embrace Uncertainty#
Detailed plans can be stifling in the face of initial unknowns. The beauty here is that we can defer many decisions until we have more information. This allows us to:
- Learn as we go: early progress will shed light on challenges and opportunities, allowing us to incorporate new learnings into our decision-making.
- Make informed decisions: by deferring non-critical choices, we can gather more data and make well-informed decisions later.
This requires always focusing on the goal: keeping a clear vision in mind helps us navigate uncertainty and prioritize tasks effectively.
Goal#
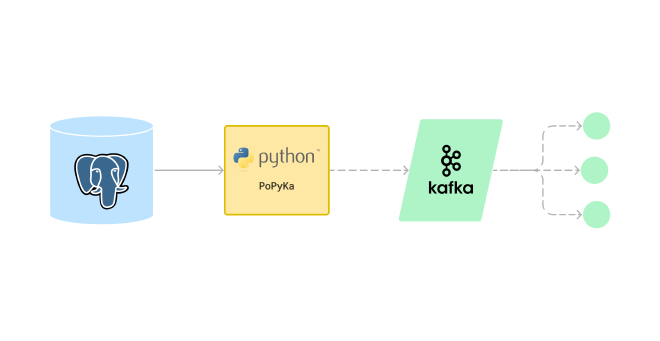
Our goal is to create a Proof of Concept (PoC) of a Change Data Capture (CDC) system (which I named PoPyKa). In essence, the system will capture real-time changes from a relational database and stream those changes… think about a very lightweight alternative to Debezium.
The potential users are:
- Users who need to validate some idea and need a CDC system that is simple and quick to set up.
- Users who want to leverage Change Data Capture (CDC) in smaller systems.

How I handle over-engineering#
When starting a new project, to help me keep everything simple, I usually think of having 3 stages with different objectives:
- Stage 1: PoC: Confirm the idea’s viability, and bring it to life.
- Stage 2: MVP: Core functionalities for a production-ready product: security, performance, observability, developer, and DevOps/SRE experience.
- Stage 3: v2, v3, etc.: I collect all my ideas here, from essential features to those that might seem a bit far-fetched.
Now, we can think about 3 different problems (the 3 stages), and focus only on the PoC:
Out of scope#
I strongly believe in the importance of clearly defining project scope. A clear understanding of what’s not included is just as crucial as what is.
By actively identifying out-of-scope features, we can focus our efforts on the core functionalities, avoiding feature creep, and leading to quicker development cycles and faster delivery of key functionalities.
For example, for the PoC:
- performance: Not important at this stage.
- resource usage: Not important at this stage.
- efficient serialization format: Not important at this stage.
- security: While security isn’t the main focus, we’ll implement basic security measures to ensure a safe environment for curious users trying out the system.
- high availability: Not important at this stage.
- easy of operation: Not important at this stage.
Scope#
- System: create the simplest Change Data Capture (CDC) system.
- Source: PostgreSQL.
- Target: Kafka.
High-level problem decomposition#
At a high level, the system will be used like this:
PostgreSQL and Kafka act as abstraction layers, allowing us to simplify our view of the system:
To start building the system, we need to break down the problem into smaller pieces. We need a way to solve one problem at a time. Here it’s easy: first, we’ll tackle how to get a continuous stream of changes from the PostgreSQL database and completely ignore anything related to Kafka.
Let’s focus on PostgreSql, and ignore Kafka for now:
Day 1 - Diving into PostgreSQL Streaming Replication#
Stream changes from PostgresSql#
We need to invest to gain agility. To accelerate development and iteration cycles, let’s leverage this powerful combination: docker compose, pytest, and TDD.
After some hours, I managed to configure PostgreSql server and made good progress from the client side, with the test_decoding plugin (this is the one used in psycopg2 documentation, so I started with it). psycopg2 is working as expected, I’m receiving the changes from PostgreSql.
Use a real decoder plugin#
The simplest next step is to use the built-in pgoutput, which is included in PostgreSql. But for some reason, it doesn’t work.
> self.start_replication_expert(
command, decode=decode, status_interval=status_interval)
E psycopg2.errors.FeatureNotSupported: client sent proto_version=0 but server only supports protocol 1 or higher
E CONTEXT: slot "pytest_logical", output plugin "pgoutput", in the startup callback
venv/lib/python3.11/site-packages/psycopg2/extras.py:616: FeatureNotSupported
Code (fails): test_start_replication_plugin_pgoutput()
This perfectly illustrates the power of problem decomposition! Initially, we focused on a simpler task: using psycopg2 to receive changes from the database. Imagine trying to tackle that initial task with a real decoder plugin at once. This likely would have been much more time-consuming.
Here’s why:
Learning Curve: You’d be dealing with both learning
psycopg2and streaming replication and potential issues withpgoutput.Debugging Challenges: As a beginner, it might be difficult to pinpoint the root cause of the
pgoutputproblem. You could spend time troubleshootingpsycopg2documentation or server configuration when the issue lies elsewhere.
Day 2 - Switching to real decoder plugin#
After some research, I discovered that managed PostgreSql from both AWS and Google Cloud offer built-in support for wal2json, making wal2json the perfect choice to implement.
The problem is, the upstream Docker image for PostgreSql doesn’t have wal2json installed, and I don’t know yet if wal2json will work at all. Jumping into the container with docker exec and manually installing wal2json is the quickest way to move forward… And in the first attempt, wal2json worked!
Code: wal2json
wal2jsonBut our development environment is kinda broken, it requires a very annoying manual step (install wal2json). Docker compose let us fix this pretty easily using build instead of image:
services:
db-wal2json:
build:
context: tests/docker/postgres-wal2json
And tests/docker/postgres-wal2json/Dockerfile:
FROM postgres:16.2
ENV DEBIAN_FRONTEND=noninteractive
RUN apt-get update && \
apt-get install -y postgresql-16-wal2json && \
rm -rf /var/lib/apt/lists/*
Another problem solved… one at a time :)
Code: db-wal2json
Huge batches of changes#
I’m using pgbench to generate DB activity, but the DB transaction has thousands of changes, making testing slow and difficult.
To keep making progress fast, it’s important to not waste time. While looking for a solution to the pgoutput issue, I found out that wal2json can send all the changes of a transaction in a single batch, or send one change at a time. That will solve the issue! If found out that wal2json can be configured to send one by one instead of batches. After looking at the code and some try and errors, I made it work.
Code: enable v2 format
Better unit-testing of core functionality#
For running some manual tests, pgbench worked well. But it’s important to make sure that the changes that we receive are consistent with the changes made in the database, and that none of the changes are lost.
We can have a bug, or maybe we didn’t even understand correctly how streaming replication works! After all, we’re learning.
It’s even more important to have an automated way to detect if something stops working. After some coding, I finished a DbActivitySimulator used on unit-test: it creates predictable changes in the DB, that allow us to verify that we receive the right data.
Messy code and poor design#
We need some refactoring, not for aesthetics, but to ensure we can continue iterating rapidly. To keep the code clean pre-commit hooks is our best friend.
Configuration#
The system needs some configuration to connect to the DB. The first idea is to use a configuration file, but the simplest solution will be to pass the configuration using environment variables.
POPYKA_DB_DSN = os.environ.get("POPYKA_DB_DSN")
"""URI: DSN to connect to PostgreSql"""
Kafka#
It’s time to add Kafka: docker compose, dependencies, and hardcoded configuration.
After everything worked as expected, we should refactor the hardcoded configuration, to be read from environment variables. There was no uncertainty here: I’ve been working with Kafka for several years now, and it makes sense to use the same configuration mechanism than for DB: environment variables.
POPYKA_DB_DSN = os.environ.get("POPYKA_DB_DSN")
"""URI: DSN to connect to PostgreSql"""
POPYKA_KAFKA_CONF_DICT = os.environ.get("POPYKA_KAFKA_CONF_DICT")
"""JSON formatted configuration of Kafka producer"""
The component that sends the messages to Kafka is pretty simple:
class ProduceToKafkaProcessor(Processor):
@staticmethod
def _get_conf() -> dict:
return json.loads(POPYKA_KAFKA_CONF_DICT)
def __init__(self):
self._producer = Producer(self._get_conf())
def process_change(self, change: Wal2JsonV2Change):
self._producer.produce(topic="popyka", value=json.dumps(change))
self._producer.flush()
logger.info("Message produced to Kafka was flush()'ed")
Code: add support for Kafka
Day 3 - Clean code & demo#
Uncertainty is gone. We have a (extremely simplistic) working PoC for a CDC. Now we need to make the code cleaner and the system easier to demo:
- I created another activity simulator, for a different purpose: to have continuously INSERT/UPDATE/DELETE in the database, so the whole system can be quickly tested (for demo purposes).
- I refactored the components. The system is small, everything is in a single python module, but after the refactor, everything makes more sense, and the code is much easier to understand.
- Added a README and set up GitLab CI/CD to build and publish a docker image, in case somebody wants to try it out.
Since everything was finished pretty fast, I added a new feature: Filter: this component filters out the changes that should be ignored, this way, they are not received by the Processors.
Code add Filter
The PoC is officially finished 🎉
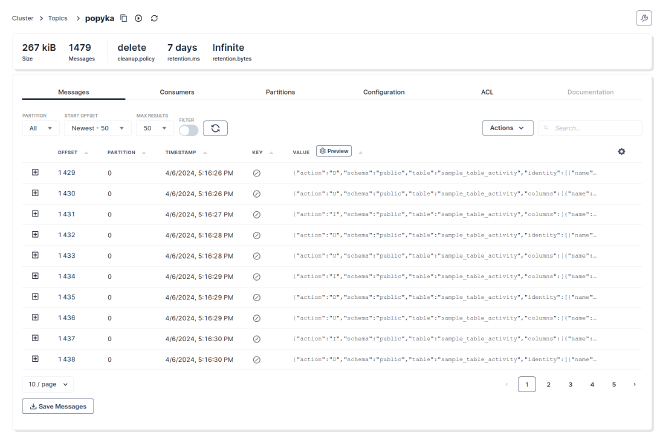
Screenshots#
Contents of the Kafka topic:
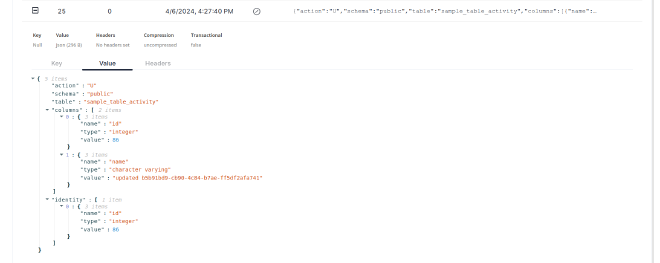
Event generated by an UPDATE:
Conclusion#
Here I want to show, at the end, how many situations were solved. And also, how many were not solved! Not having to worry about performance, resource usage, etc. is important to be able to pick the simplest solutions.
Uncertainty was decreasing in each iteration.
The complexity was managed: looking always for the most simple solution to solve one problem at a time.
Maintainability is important, even in a PoC: after solving a problem, it’s important to check the code and decide if it’s time to refactor. Because we have unit-test, refactors are cheap. Because we refactored, we will be able to keep moving fast in the next iterations.